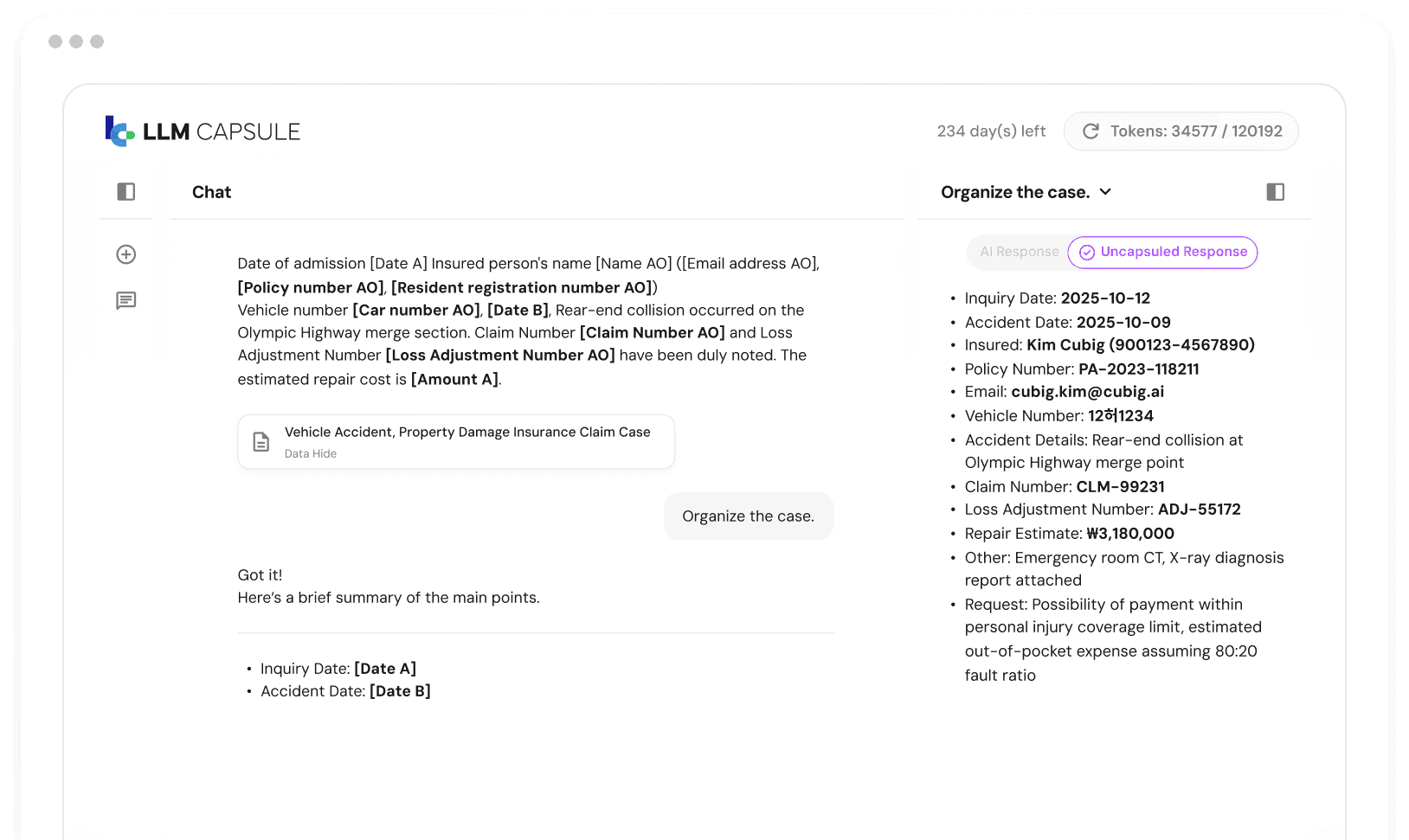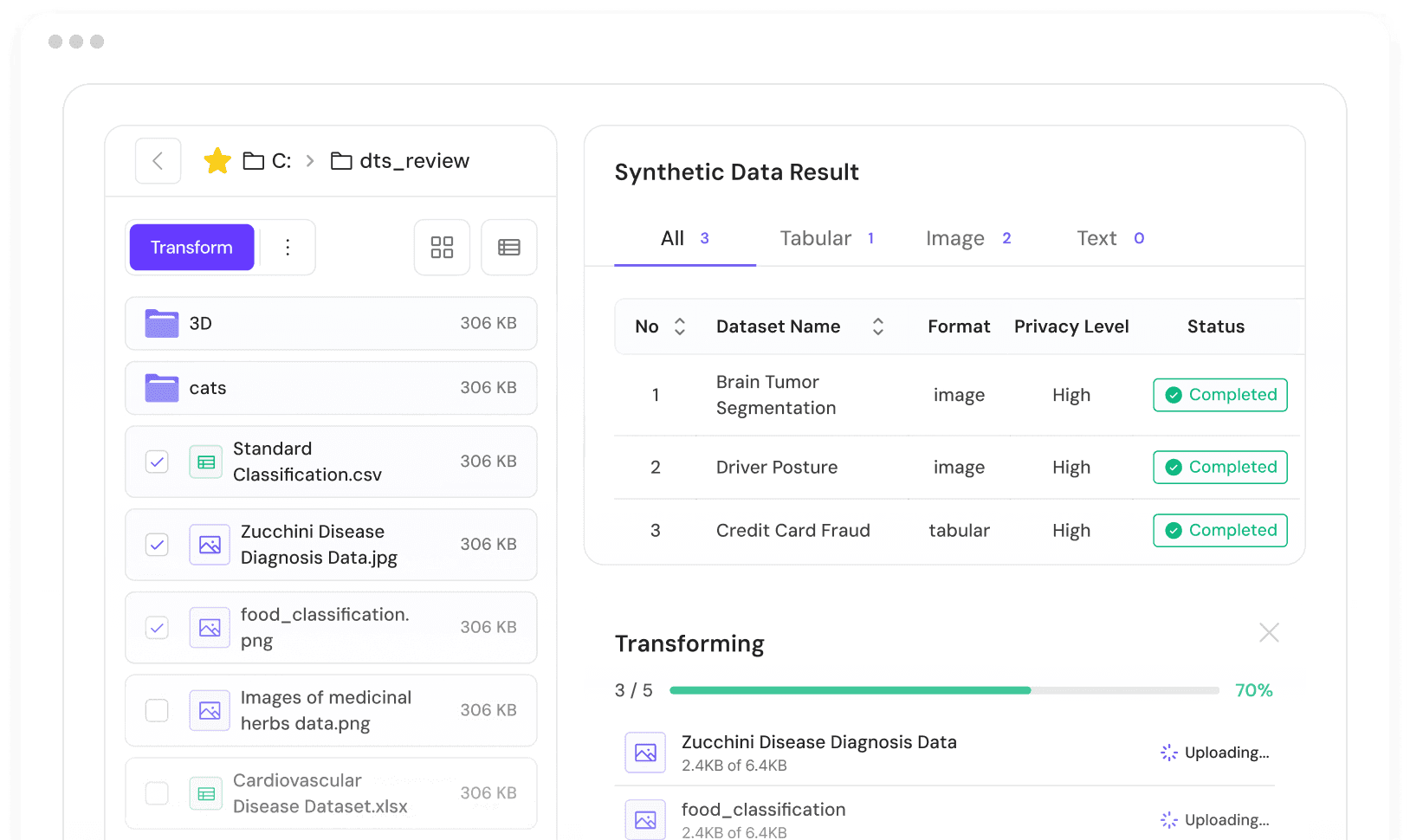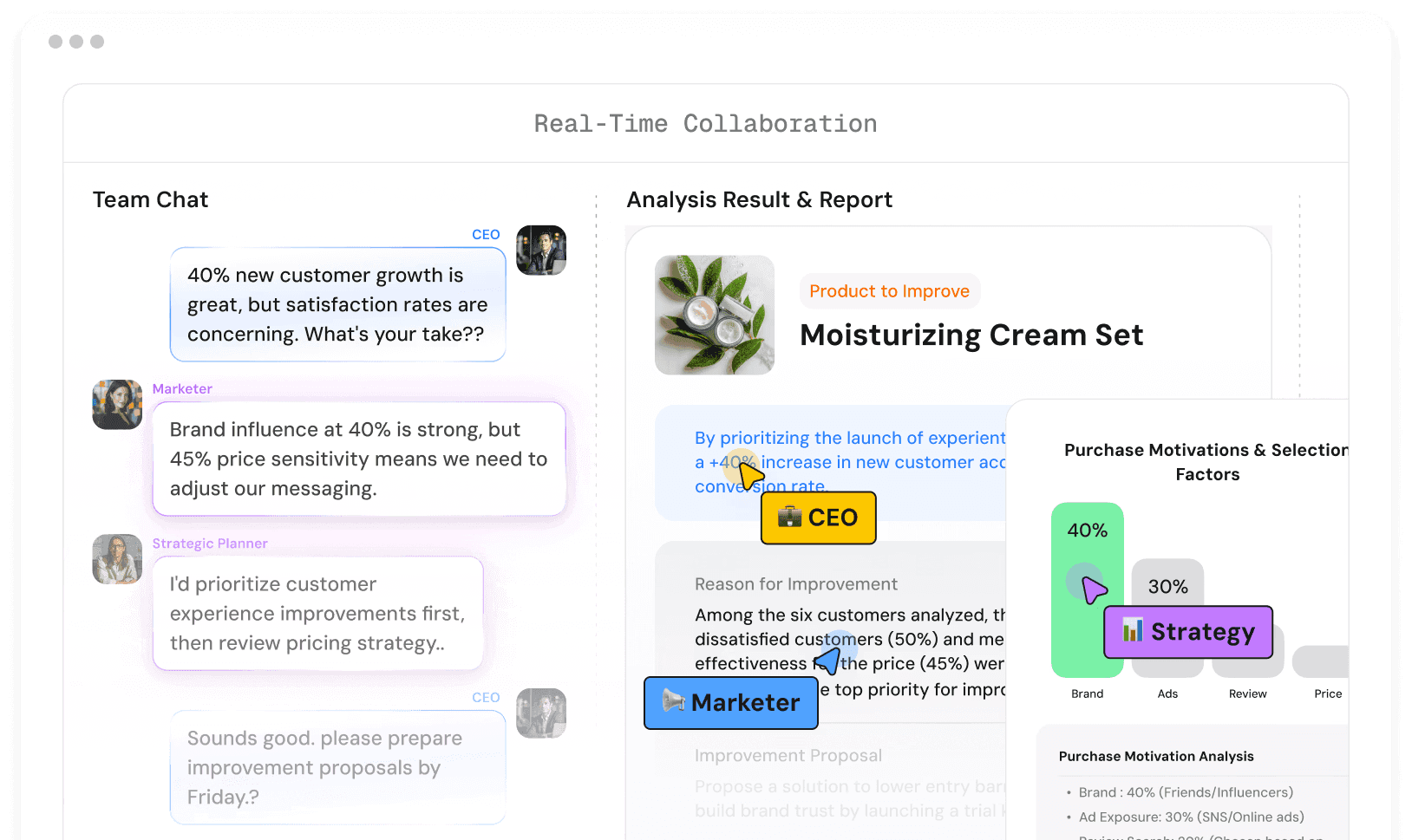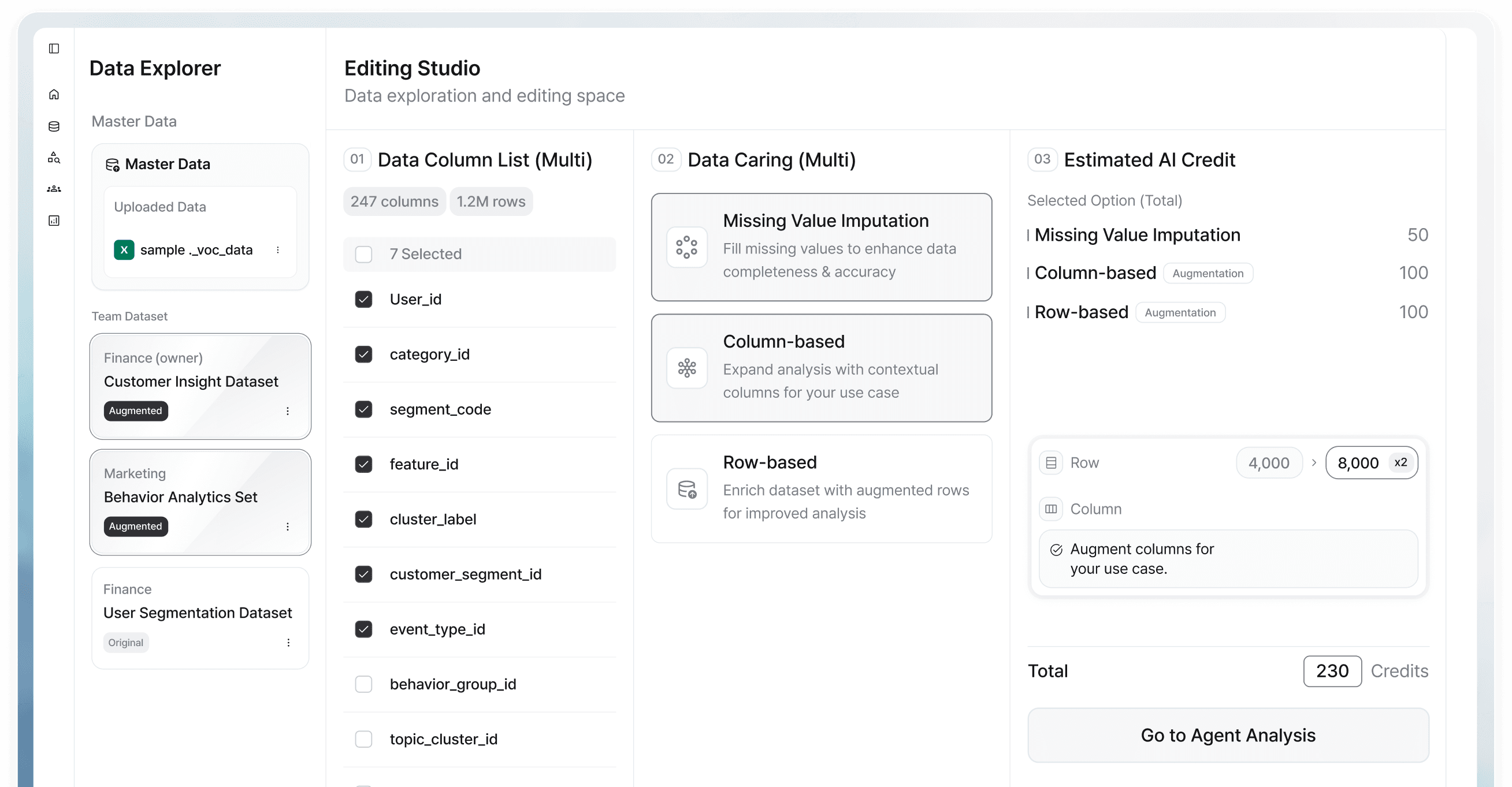













"We want to use LLMs on enterprise data, but sensitive fields block us."
PII, internal identifiers, regulated records — employees can't send this to an LLM. Compliance blocks adoption. Projects stall.
CUBIG SOLUTION
LLM Capsule
removes the blocker
Available on AWS Marketplace. GS Certified
Explore LLM Capsule →