"엔터프라이즈 데이터에 LLM을 쓰고 싶지만, 민감 필드가 가로막고 있습니다."
PII, 내부 식별자, 규제 대상 기록 — 직원들이 LLM에 보낼 수 없습니다. 컴플라이언스가 도입을 막고 프로젝트가 정체됩니다.
기업의 AI 도입을 가로막는 세 가지: 법적으로 활용할 수 없는 데이터, 존재하지만 불완전해 모델 학습에 사용할 수 없는 데이터, 그리고 운영 환경에서 재현되지 않는 결과. CUBIG는 이 세 가지를 모두 해결하는 AI-Ready 데이터 인프라입니다.
AI가 실제로 활용할 수 있도록 데이터를 복원·재균형·안전 보강하여 합성 데이터 레이어로 전환하세요.













배포 후 AI가 실패하는 이유는 분명합니다. 데이터가 제한되어 있고, 활용할 수 없거나 운영 환경에서 상태가 불안정하기 때문입니다.
60%
2026년까지 AI 최적화 데이터 인프라를 갖추지 못하면 AI 프로젝트의 실패 비율
30%
PoC 이후 제품화 단계에 이르기 전에 중단된 GenAI 프로젝트의 비중
42%
AI 프로젝트를 중단한 미국 기업 비율 (전년 17%에서 증가)
AI 시스템이 실제 운영 환경에서 실패할 때, 비용은 모델 자체가 아닙니다. 팀은 원인을 찾는 데 며칠 혹은 몇 주를 소모합니다. 모델을 점검하고, 파이프라인을 재학습하고, 데이터셋을 재구성하지만 어떤 실행 조건이 달라졌는지 알 수 없습니다. 실행 추적 없이는 디버깅이 추측에 의존하게 됩니다.
이러한 문제는 AI 배포 주기를 늦추고 프로덕션 시스템에 대한 조직의 신뢰를 떨어뜨립니다. 개발 환경에서 정상 작동하던 프로젝트도 배포 후 우선순위에서 밀려납니다. 모델이 잘못되어서가 아니라, 배포 이후 결과가 왜 달라졌는지 누구도 신뢰성 있게 설명하지 못하기 때문입니다.
민감 정보는 보호되면서도 데이터는 AI 워크플로우에서 계속 활용 가능하고 규정을 준수합니다.
데이터를 저장만 하거나 부분적으로만 접근하는 것이 아니라, 학습·검증·의사결정에 실제로 활용할 수 있습니다.
환경, 스키마, 파이프라인이 바뀌어도 AI 실행 결과를 재현할 수 있습니다.
기업 데이터를 활용 가능하고, 프라이버시가 보호되며, 운영 환경에서 AI가 안정적으로 실행되도록 만드는 인프라입니다.
CUBIG의 AI-Ready 데이터는 규제 장벽 없이 활용 가능하고,
맥락이 보존되며, 문제가 발생해도 완전히 추적할 수 있는 데이터를 의미합니다.
정형 & 비정형
Fixes unusable data · data-level privacy
fixes unstable execution
fixes inference-level privacy
Stable production models · rare-event coverage
Privacy-safe insights · churn prediction
Survey · price strategy · instant research
What-if scenarios · regulatory impact
LLM on internal data · RAG · PII-safe
Enterprise RAG · secure knowledge base
Schema fingerprinting · version-locked runs
ISO 27001 · ISO 42001 · GS 인증 · AWS Marketplace · 특허 10+건
기업의 AI 실패는 우연이 아닙니다. 세 가지 구조적 장애물 중 하나로 귀결됩니다. 당신의 문제를 찾아보세요.
"엔터프라이즈 데이터에 LLM을 쓰고 싶지만, 민감 필드가 가로막고 있습니다."
"데이터는 있지만, 제한되거나 불균형하거나 학습에 쓰기에 너무 불완전합니다."
"PoC에선 작동했지만 운영 환경에서 실패하거나 일관성 없는 결과를 냅니다."
개인식별정보(PII), 내부 식별자, 규제 대상 기록 — 직원들이 LLM에 전송할 수 없습니다. 규정 준수가 도입을 막고, 프로젝트가 멈춥니다.
접근 제어, 커버리지 부족, 희소 클래스, 프라이버시 제약 — 데이터는 있지만 AI는 사용할 수 없습니다. 프로젝트를 시작할 수 없습니다.
스키마 변경, 파이프라인 업데이트, 조용한 데이터 변경 — 운영 환경은 결코 고정적이지 않습니다. 배포 후 결과가 달라지고, 근본 원인을 찾는 데 몇 주가 걸립니다.
Databricks, Snowflake, dbt는 스토리지, 쿼리, 파이프라인을 해결합니다.
이들은 AI 실행 안정성, 민감 데이터 차단, 사용 불가능한 학습 데이터를 해결하지 않습니다.
이것은 다른 레이어입니다. CUBIG가 만드는 레이어입니다.
세 가지 뚜렷한 진입점. 각각은 특정한 운영 차단 요소와 연결됩니다.
팀은 보통 하나로 들어와 그곳에서 확장합니다.
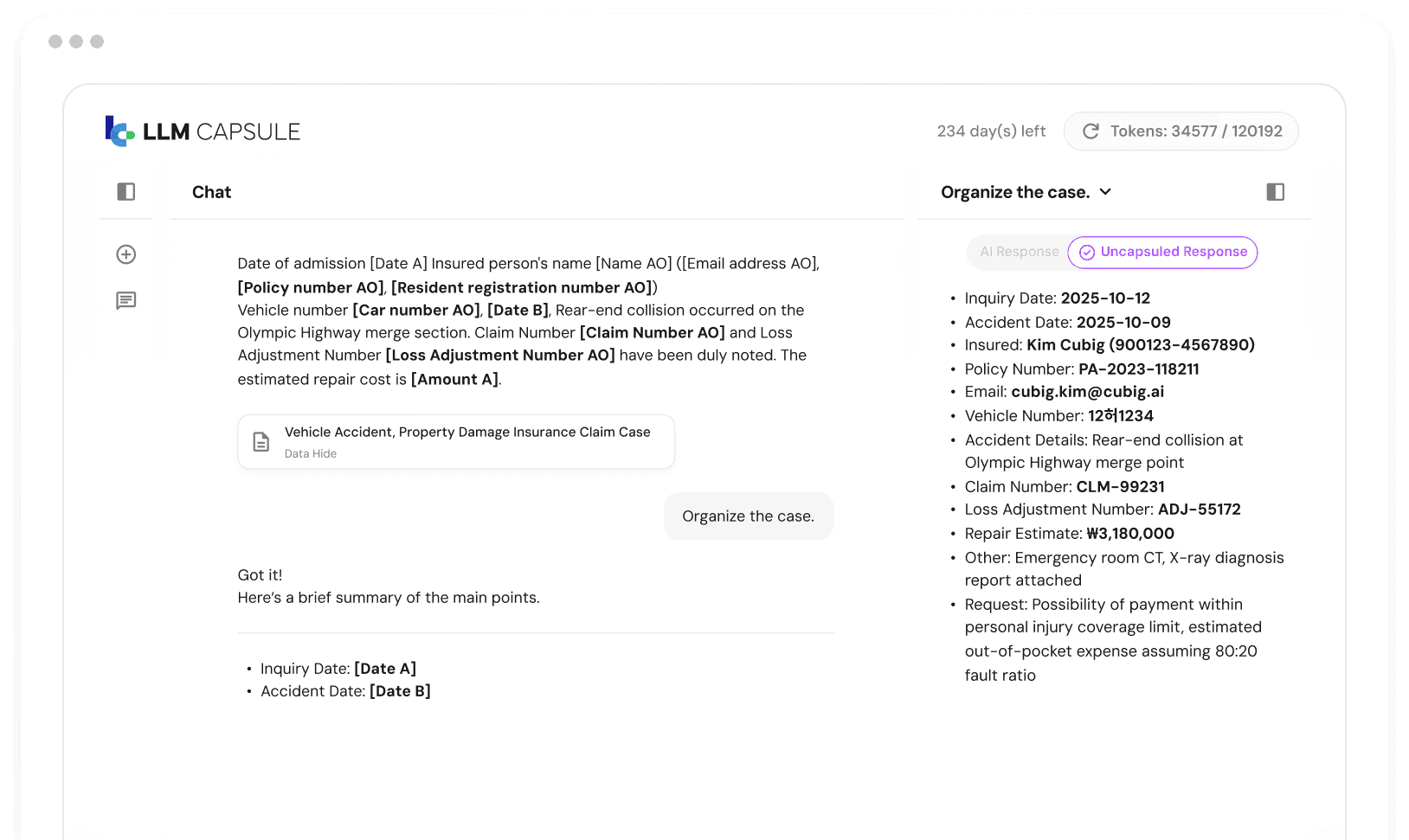
외부 LLM API를 도입하는 팀은 기업 문서에 안전하게 전송할 수 없는 민감한 필드가 포함되어 있다는 점을 발견합니다.
컴플라이언스가 도입을 막고, 프로젝트는 데이터 접근 계층에서 멈춥니다.
LLM Capsule은 LLM 상호작용 중 민감 데이터를 인라인으로 익명화해 이 장애물을 제거합니다. PII는 절대 외부 모델에 도달하지 않습니다.
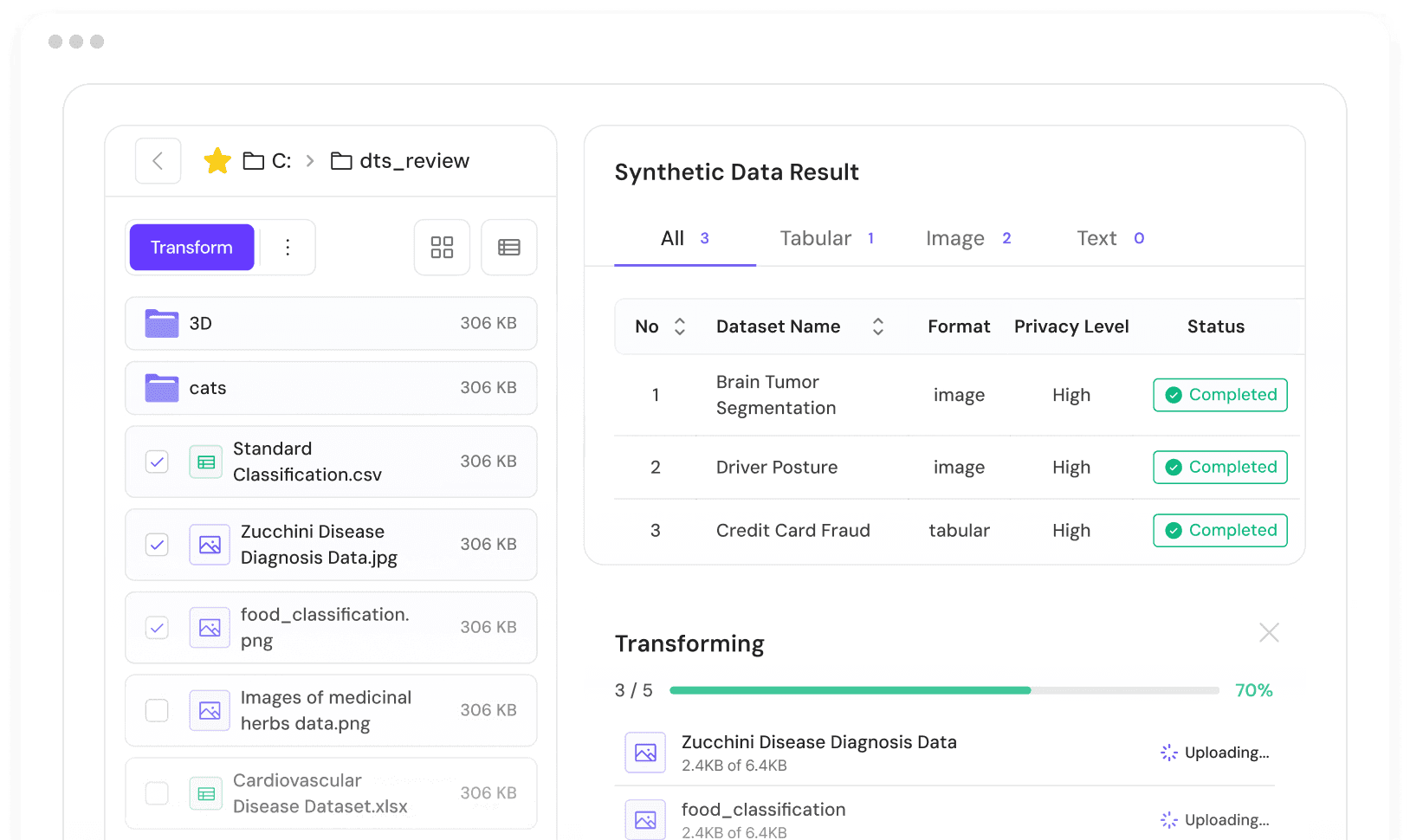
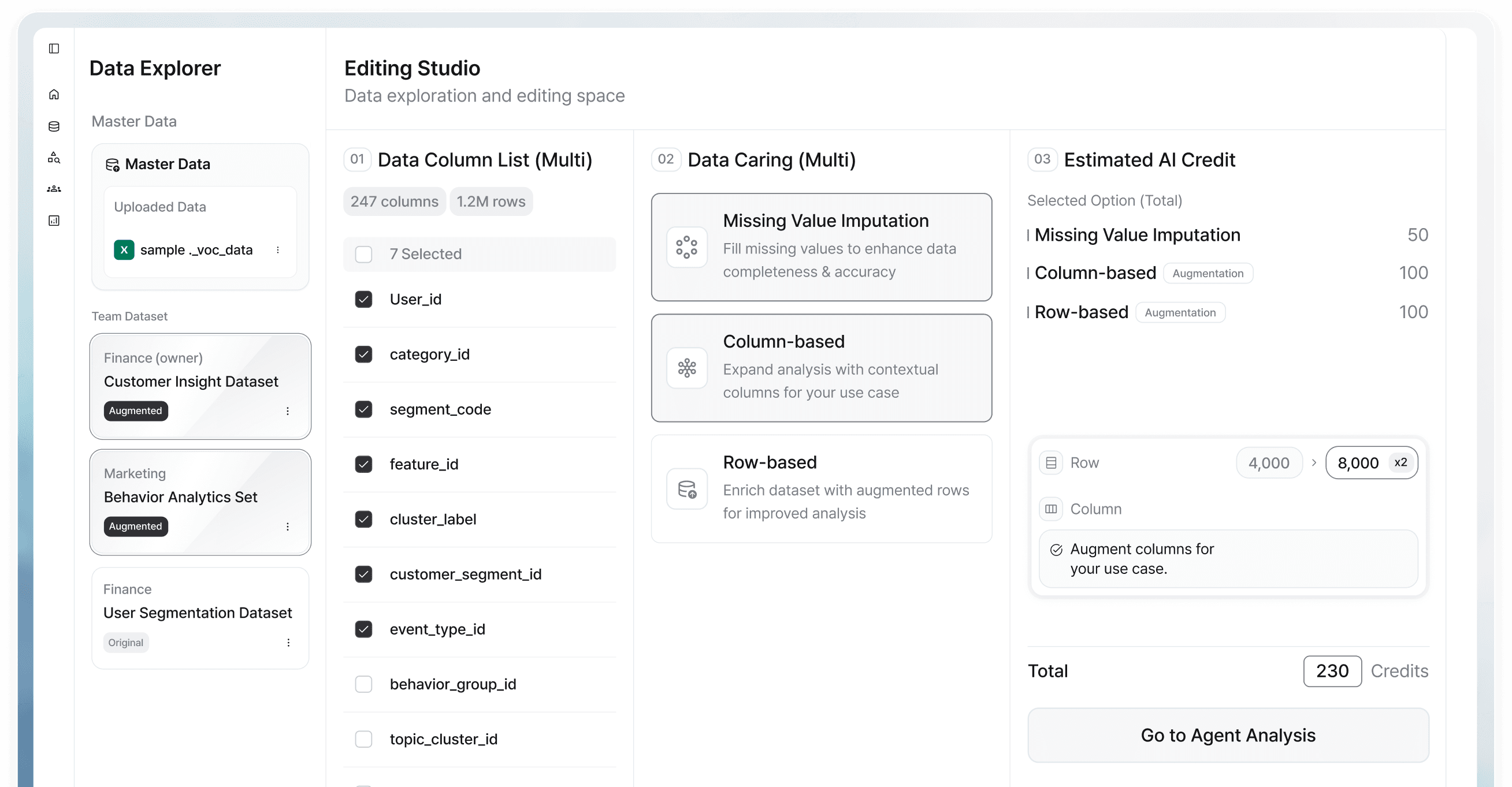
분류·탐지 모델을 만드는 팀은 희귀 클래스가 부족하거나, 프라이버시 규칙 때문에 원본 데이터를 쓸 수 없거나, 접근 제한이 파이프라인을 완전히 막는 상황을 자주 만납니다. 데이터는 있지만 쓸 수 없습니다.
DTS는 실제 데이터가 제한되거나 불완전할 때, 커버리지를 확장하고 불균형을 바로잡는 프라이버시 보호 합성 데이터셋을 생성합니다.
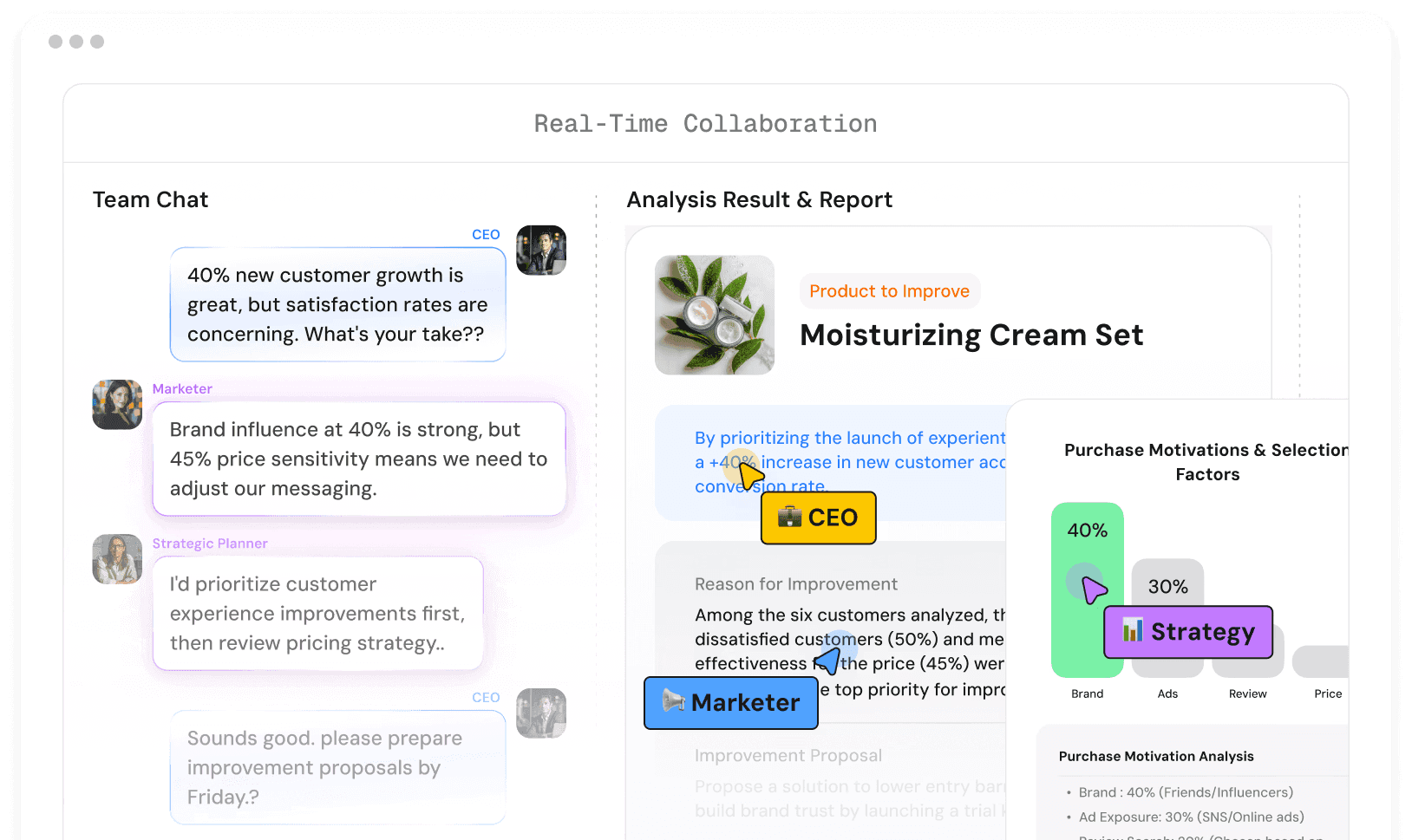
운영 AI 파이프라인을 다루는 팀은 모델을 바꾸지 않았는데 결과가 달라지는 상황을 겪습니다. 스키마 드리프트, 파이프라인 변경, 런타임 변동입니다. 어떤 실행 조건이 달라졌는지 분리할 추적 계층이 없어 디버깅에 몇 주가 걸립니다.
SynTitan은 모든 AI 실행을 버전이 있는 Release State에 바인딩합니다. 실행 조건이 추적 가능하고, 비교 가능하며, 언제든 재현 가능해집니다.
실제 기업 환경에서의 배포 패턴이며, 각각은 CUBIG 인프라가 제거한 특정 운영 차단 요소를 반영합니다.
이상 탐지 신뢰도 개선 및 희귀 사건 클래스 검증 범위 확대.
어떤 단계에서도 개인정보를 노출하지 않고 고객 인사이트를 생성하고 분석 파이프라인을 이어갑니다.
불만 분류 정확도 향상. 원본 고객 기록을 노출하지 않고 팀 간 분석이 가능해졌습니다.
여론 주도자의 영향력과 정책 인식 변화를 이슈로 확산되기 전에 미리 감지합니다.
설문 응답자의 개인정보를 수집하지 않고도 트렌드 인사이트를 훨씬 빠르게 전달합니다.
분산된 데이터를 안정적인 운영 파이프라인으로 통합하여, 명확한 행동 인사이트와 커뮤니티 반응 흐름을 제공합니다.
운영 환경 AI 실패는 사건 복구에 몇 주가 소요됩니다.
근본 원인은 거의 항상 데이터나 실행 상태입니다 — 모델이 아닙니다.
30분 안에 귀 사의 원인을 찾아봅시다.
30분 아키텍처 리뷰 · 부담 없는 상담 · 엔지니어와 직접 논의 가능
접근 통제, 감사 로깅, 책임 분리가 운영 워크플로우에 내장됩니다.
환경 전반에 걸쳐 데이터 리니지, 변환, AI 실행 상태의 완전한 추적성을 제공합니다.
규제 산업에서 운영하도록 설계되었으며, 엔터프라이즈급 데이터 처리 원칙을 전반에 적용합니다.
엔터프라이즈 마켓플레이스 채널에서 이용 가능합니다. 첫 상담부터 조달 프로세스를 지원합니다.
온프레미스, 클라우드, 엔터프라이즈 마켓플레이스 배포. 기존 인프라와 보안 태세에 맞춰 유연하게 적용합니다.
원시 데이터 경계 강제, 데이터 최소화, 정책 기반 처리를 모든 워크플로우에 적용합니다.
PoC 벤더가 아닙니다. 기업에게 부족했던 프로덕션 AI 인프라 레이어입니다.
PoC 벤더가 아닙니다. 기업에 부족했던 프로덕션 AI 인프라 레이어입니다.
수상 및 인증 10+건 (장관상 4건, GS · KISA 포함)
특허 10건 (국내 8건 중 등록 3건, 해외 2건)
설립 · 성남시, 대한민국 · UK 법인 설립







CUBIG와 함께 합성 데이터의 모든 잠재력을 열어보세요. 원본을 노출하지 않고도 산업 전반의 멀티모달 데이터를 생성·통합·검증·확장할 수 있습니다.
CUBIG 문의하기 →